查看告警记录
数据雷达提供了多种分类分级算法,包括AI大模型算法、正则算法、字典算法和应用算法,旨在满足用户不同的分类需求,提高数据分类的准确性和效率。自定义算法分组:通过自定义算法分组,用户可以根据算法的功能、用途或者行业领域等因素进行分类,将具有相似特性或者功能的算法归类到同一个分组下。这样一来,用户可以更快速地找到需要的算法,同时也可以更清晰地了解系统中各个算法的分类和属性。分类分级算法共享:所有用户均可在分类分级算法组织架构下共享这些算法,提升了协作效率和资源利用率。数据分类分级算法能够为企业提供高效、准确的数据分类和分级服务,帮助企业更好地管理和保护数据资产,降低数据泄露和滥用的风险,提升数据安全性和合规性水平,增强企业对数据的控制能力,从而提升企业的运营效率和竞争力。数据网关(DG)通过多项功能实现精细化的数据访问控制。查看告警记录
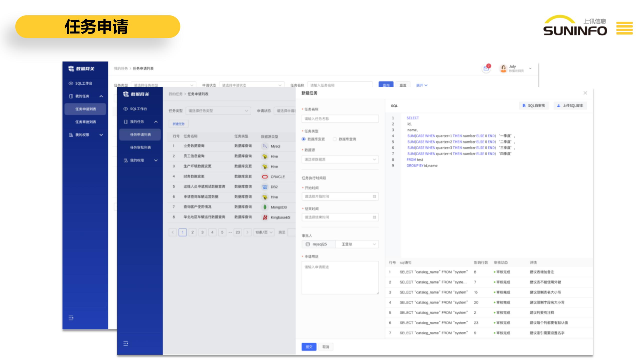
数据雷达提供了多种分类分级算法,包括AI大模型算法、正则算法、字典算法和应用算法,旨在满足用户不同的分类需求,提高数据分类的准确性和效率。正则算法:(1)自定义正则:用户可以通过编写正则算法来对数据进行分类分级,根据自身业务需求,灵活定义匹配规则,实现数据的准确分类。(2)多字段打标支持:支持多字段方式,用户可以针对多个字段进行正则匹配,并根据匹配结果对数据的级别和类别进行打标,实现更加精细化的数据分类。(3)多算法配置:用户可同时配置多个正则算法进行逻辑操作,包括与、或、非等功能。通过组合不同的正则算法,可以实现更复杂的数据分类逻辑,提升分类准确性和灵活性。一站式上讯数据网关资质上讯信息技术自主研发的数据网关DG通过对数据库操作人员的细颗粒度权限管控、敏感数据动态脱敏等。

上讯数据网关DG数据源管理主要具备以下能力:连通性测试:为确保数据源的可用性,数据源支持对数据源连通性的测试功能,及时发现数据库连接问题,提高数据管理的稳定性。实时数据更新:数据网关DG能够实时更新数据源中的数据,以确保系统获取到***的业务信息,保障数据的准确性和实效性。批量导入数据源:提供模板化、批量导入数据源的功能,以简化大规模数据源的配置流程,提高操作效率。快速发现数据源:数据源管理需具备快速发现数据源的能力,可以根据局域网IP段和指定数据源端口迅速发现数据源,提高系统自动发现的效率。域名通信管理:针对域名通信的数据源,支持在hosts配置中添加域名和IP映射关系,代替后台操作,以提供更为便捷的数据源管理方式,符合日常操作习惯。访问控制管理:支持对数据库进行访问控制管理,限定只有指定的数据库客户端、数据库账号、访问IP及数据库账号、访问IP,才能访问访问数据库,有效确保数据库的访问安全。
2018年的万豪酒店事件。在这起事件中,黑客成功越过了酒店数据库的安全防护,未经授权地访问了数据库,导致超过3亿客户的个人信息被泄露。这些信息包括了客户的姓名、联系方式、信用卡信息等敏感数据。这一泄露事件引起了广泛的关注和愤慨,不仅对万豪酒店的声誉造成了重大影响,也对客户的隐私权产生了严重威胁,甚至可能引发法律诉讼。上海上讯信息技术股份有限公司自主研发的数据网关DG通过对数据库操作人员的细颗粒度权限管控、敏感数据动态脱敏、SQL审核、高危操作管控等,实现运维过程中的事前预防、事中管控和事后审计,为数据库管理者提供简单高效的数据管控解决方案,满足内部数据安全保护需求和外部监管要求。
数据网关DG操作日志及审计功能应能够提供全方面的、可追溯的操作记录。
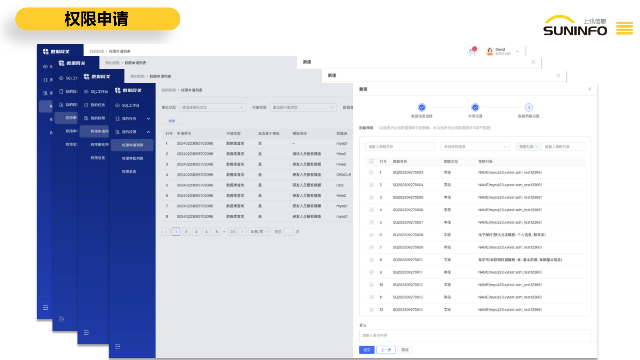
在当今数字化的商业环境中,数据网管对于保障业务连续性至关重要。无论是在线交易、客户服务还是内部运营,任何网络中断都可能导致业务停滞和经济损失。数据网管通过建立冗余网络架构来确保业务的连续性。这意味着在主要网络组件出现故障时,备用设备和链路能够立即接管,确保数据的传输不受影响。他们还会定期进行业务影响分析,评估不同网络故障对业务流程的潜在影响,并制定相应的应对策略。例如,对于一个依赖实时数据处理的金融机构,数据网管会确保网络的高可用性,以避免交易延迟或中断。他们会监控网络设备的运行状态,提前发现潜在的故障隐患,并及时进行维护和升级。通过这些努力,数据网管为企业提供了一个稳定可靠的网络环境,使业务能够持续运行,不受网络问题的干扰!全方面兼容性:数据源管理具备高度的兼容性,能够适配多样化的数据库平台。什么是上讯数据网关优势
数据网关DG是数据库管理的主要工具,具有一些功能特点,以强化权限管理,确保数据的安全性和可控性。查看告警记录
数据雷达DR基于AI大模型进行分类分级:在实现数据分类分级的过程中,语义级别的数据分类分级引擎采用了基于AI大模型的先进技术。这一引擎能够同时对数据类型进行词法、语法和语义级别的特征提取和分析,从而建立起语义级别的高维度特征向量。通过这种方式,引擎能够更加准确地理解和区分不同类型的数据,提高了数据分类分级的精确度和可信度。基于数据字段内容的模型训练,保证了数据分类分级模型的可复制性:语义级别的数据分类分级引擎注重保证数据分类分级模型的可复制性,采用AI大模型进行训练时,引擎不依赖于数据字段的名称和注释,即使在没有明确的字段描述情况下也能够达到很高的准确度。这意味着训练后的数据分类分级模型在不同的数据环境下都能够稳定可靠地运行,具有很高的适用性和通用性,为数据管理和安全保障提供可靠的支持和保障。 查看告警记录
- 南京信息化企业数据安全解决方案直销价格 2025-08-02
- 崇明区如何企业形象策划热线 2025-08-02
- 一站式信息流广告营销平台 2025-08-02
- 泰山区数据AI营销包含 2025-08-02
- 软包装采购管理平台 2025-08-02
- 闵行区品牌财务咨询服务电话 2025-08-02
- 广州品牌策划方案 2025-08-02
- 株洲哪个企业企业管理咨询服务值得推荐 2025-08-02
- 全过程实用新型专利代理共同合作 2025-08-02
- 湖北运营臻推宝电子智能名片介绍 2025-08-02